
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица, размещенная на странице СР1251 соответствующего стандарта, которая используется в операционных системах семейства Windows фирмы Microsoft (рис. 3.2, б). Во всех представленных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 216 = 65536 различных символов. На рис. 3.4 приведена кодовая таблица 0400 (русский алфавит) стандарта Unicode.
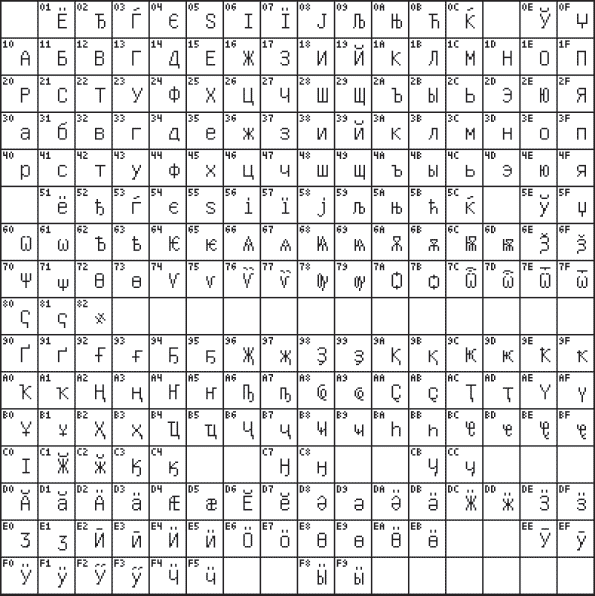
Рис. 3.4. Кодовая таблица 0400 стандарта Unicode
Поясним сказанное, касающееся кодирования текстовой информации, на примере.
Пример 3.1Закодировать слово «Компьютер» в виде последовательности десятичных и шестнадцатеричных чисел, используя кодировку СР1251. Какие символы будут отображены в кодовых таблицах СР866 и КОИ8-Р при использовании полученного кода.
Последовательности шестнадцатеричного и двоичного кода слова «Компьютер» на основе кодировочной таблицы СР1251 (см. рис. 3.3, б) будут выглядеть следующим образом:

Данная кодовая последовательность в кодировках СР866 и КОИ8-Р приведет к отображению следующих символов:
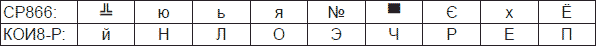
Для преобразования русскоязычных текстовых документов из одного стандарта кодирования текстовой информации в другой используются специальные программы – конверторы.